How to setup your own ChatGPT and connect it to your own data
TLDR: I'm going through a simple POC (Proof of Concept) how companies can setup their own ChatGPT-like professional agents without sending their confidential data to OpenAI or to any other online service. After a general introduction to how LLMs are trained, I show how you can use Dolly (a publicly available and commercially usable fine-tuned language model) and Langchain (an open-source NLP library) to make your own data sources (e.g. from documents, databases, other systems) accessible via natural language using vector data stores and semantic search.

Just as I was thinking that we are about to enter another AI winter, OpenAI broke the news with ChatGPT. Ever since, no day goes by without some startling news about ChatGPT's astonishing, and somewhat inconceivable, capabilities.
A technical writing-aid on steroids, ChatGPT can literally comment about anything that you ask it about and will revert with a sensible, grammatically correct response. And apparently it does so in 95 different languages. Impressive!
Taking the Internet by storm
After its launch in late 2022, ChatGPT has taken the entire Internet by storm. It now ranks as the fastest application or platform ever to accumulate 100 million users: only 2 months. Growing faster than Tik Tok or any other social media app.
Fluency without understanding
What sets it apart from its dated ancestors Siri, Alexa and Cortana is its mind-blowing ability to digest long, complex human inputs, now called prompts. It systematically deconstructs and creatively re-assembles sentences and is able to produce (what seems to be) meaningful outputs.
Does this mean that ChatGPT actually understands human language and the meaning of our questions and its own answers? No. Absolutely not.
Make no mistake. Don't be fooled by the flawless prose that ChatGPT generates. It's simply comparing users' queries to everything it has been fed in the past, and assembles text that, by measure of statistical probability, likely looks meaningful in the given context.
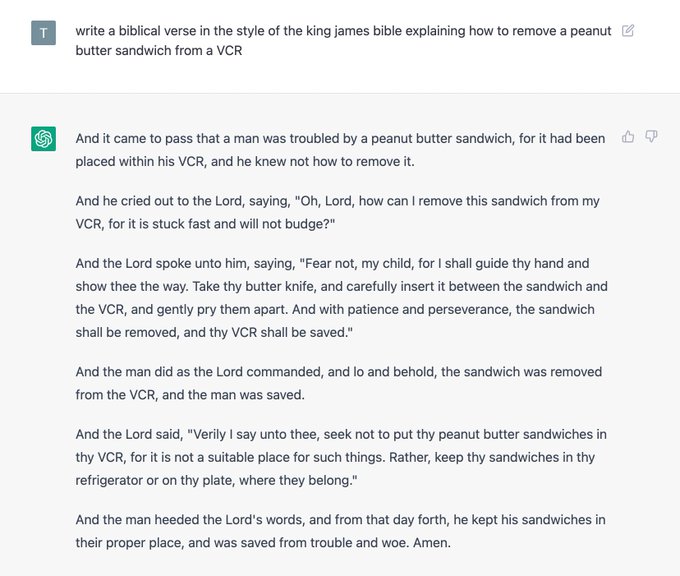
In doing so, it may completely make up "facts" and generate grammatically correct non-sense. Commonly now referred to as hallucination, ChatGPT's creative nature has no limits. Reader discretion is advised. A funny example I found is a Twitter user asking ChatGPT to write a biblical verse explaining how to remove a peanut butter sandwich from a VCR. LOL
See ChatGPT's flawless response below, and further examples here.
With all that being said about ChatGPT's short-comings and potential risks, there's also a tremendous upside to using the technology productively in an enterprise setting. But how?
Issues for commercial usage
As soon as you explore the idea of leveraging ChatGPT, or other alike systems for that matter, commercially, a number of issues are typically raised at once, including:
- lack of domain expertise
- data privacy and data protection
- cost
Lack of domain expertise
Most large language models (LLMs) have been trained on humongous, generic, publicly available data sets. The Pile, for example, is a >800 GB Dataset of Diverse Text for Language Modeling which you can download here.
As such, the LLM's knowledge of the world is limited to information that is publicly available. It won't have any knowledge of company-internal, proprietary data such as customer information, project references, internal documents such as contracts, financial reports, etc. Yet, it is exactly this domain expertise that harnesses the largest potential for a prudent, intelligent professional agent to add value in a business setting.
So the question is, how can we apply the power of LLMs and GPT (generative pre-trained transformers) technology to a specific domain?
And if we actually do provide ChatGPT with access to any domain-specific knowledge, how do we protect data privacy and intellectual property?
Data privacy and data protection
OpenAI offers ChatGPT as a free service via its own website, as well as via a $20 ChatGPT Plus subscription. The direct service on their website can be very tempting to play with.
When you do, keep in mind though that all user input is not only shared with OpenAI for processing but also used by OpenAI to further "improve the service" as the company's Terms of Use clearly point out.
This means, users' chats are directly used to further train the model and improve future versions. When your staff, for example, share meeting write-ups with ChatGPT to quickly produce meeting minutes, or when your developers feed proprietary source code to ChatGPT to quickly find a coding bug, they're effectively leaking confidential data. Both cases actually happened at Samsung. Oops!
While leaking proprietary information to OpenAI is already bad enough, things get even more ugly if the OpenAI platform itself has bugs and accidentally shares one user's data with other users. Unfortunately, this as well actually happened. Oops^2!
The risks of using ChatGPT as a service in a company setting quickly become clear. But there's more.
As an alternative to using the direct service on the OpenAI website, the more interesting offering is the company's API service which allows developers to connect and empower any application with ChatGPT capabilities.
And According to OpenAI's data usage policies
OpenAI will not use data submitted by customers via our API to train or improve our models
which is great. This means, while for the direct chat service there's an opt-out policy (i.e. if you don't explicitly opt-out your data will be used), for the API it's opt-in (i.e. by default your data will not be used but you can explicitly allow OpenAI to use your data if you want to).
So, should this make companies feel better to use ChatGPT via the API in a professional setting? Yes. Does it fully address the concern of protecting data privacy and proprietary information? No.
Why not? Well, companies are still sending their proprietary information to OpenAI where OpenAI's employees will have access to this data. OpenAI explicitly mentions this in their data usage policies:
OpenAI retains API data for 30 days for abuse and misuse monitoring purposes. A limited number of authorized OpenAI employees, as well as specialized third-party contractors that are subject to confidentiality and security obligations, can access this data solely to investigate and verify suspected abuse.
So, while the data you shared via the API is not directly used by OpenAI anymore to further improve their service, it is still accessible by their employees. For many business use cases, this type of potential external access may render the service unusable commercially.
Cost
The third concern that is typically considered by companies when exploring a ChatGPT-like service in a professional setting is cost.
OpenAI's charges for ChatGPT are based on the number of words, or tokens, that you feed into the API. Pricing also depends on what specific model you use. While ChatGPT (based on GPT-3.5) is currently priced at $0.002 per 1,000 tokens (which roughly translates into 750 words), the latest and most advanced model, GPT-4, is priced at $0.06 per 1,000 tokens when using the largest possible context of 32k tokens. A jaw-dropping 3,000% increase from version 3.5 to version 4. Ouch!
While the unit charges seem low, total usage fees quickly add up. Especially, if your organization has a large amount of users. And in a business setting, this type of variable, usage-dependent cost do matter.
LLMs under the hood
To address the above concerns about lack of domain expertise, data privacy and cost, companies may want to explore setting up their own ChatGPT. And so do I.
Is this feasible? And if so, how to do so?
I wanted to to explore these questions and therefore created a simple POC using publicly available data sets and Open Source technology.
But before we get there, let me make a small detour and dive a bit deeper into how ChatGPT actually works.
Training a language model
Large language models are typically trained in 2 steps: pre-training and fine-tuning.
Pre-training
During pre-training, large text corpora such as The Pile are processed using different flavors of the transformer technology and other NLP tools.
The transformer network architecture has been around for a few years already. Back in 2017, researchers at Google Brain introduced the transformer idea in their ground-breaking paper "Attention is all you need". The main contribution of transformers to NLP was the introduction of an attention mechanism.
Two techniques in particular are being used for training: next token prediction and masked language modeling. Both basically utilize statistical probabilities of words to appear in the same context. With transformers, neural networks started to be able to consider the context that a given text is presented in. Since all meaning in language is context-sensitive this presented a real break-through.
Ever since, transformers have by and large replaced recurrent and convolutional networks in NLP and have become the de-facto weapon of choice for NLP engineers worldwide.
Foundation models
The training process is compute-intensive and can take several days to complete. The result is a language model that is capable of incrementally predicting the next word in a sentence. It detects structure and patterns in language, identifies relationships between words and sentences, and fluently produces grammatically correct outputs.
Those base models form the generic foundation for a wide range of more specialized downstream tasks and hence are referred to as foundation models.
The most popular foundation models include: extracted from Wikipedia:
| Model | Release date | Developer | Number of parameters | Corpus size |
|---|---|---|---|---|
| BERT | 2018 | 340 million | 3.3 billion words | |
| GPT-3 | 2020 | OpenAI | 175 billion | 499 billion words |
| LLaMA | February 2023 | Meta | 65 billion | 1.4 trillion words |
Open foundation models
Unfortunately, most of those foundation models were kept closed source by their creators, and so it didn't take long for a growing number of open alternatives to emerge in the NLP community:
- Big Science’s Bloom (trained on a French supercomputer, sponsored by the French government)
- EleutherAI’s Pythia
- H2O.ai’s h2ogpt
- OpenLLaMA
The availability of such open models has greatly facilitated and further accelerated the rapid, continuous evolution of LLMs.
What foundation models are missing though is the ability to follow instructions, hold conversations (dialog) and apply logic (reasoning). No matter how many times you read all books, blogs, websites, etc. ever written in the entire history of mankind, you won't learn reasoning from simply processing prose text.
To make the foundation model more useful for different use cases, for example to power a chat bot, the model needs to be further refined or fine-tuned.
Fine-tuning
OpenAI creatively combined the 5-years-old transformer technology with other machine learning training mechanisms, in particular with supervised learning and reinforcement learning to inject desired capabilities such as instruction-following, dialog and reasoning into the foundation model.

The fine-tuning can be split into 2 major steps:
- instruction and conversation tuning
- Reinforcement Learning with Human Feedback
Instruction and conversation tuning
The pre-trained foundation model is first fine-tuned using supervised learning. In supervised learning, a machine learning model is taught by humans what a correct behavior should look like. In practice, this means researchers create a new data set of arbitrarily collected prompts and ask a group human labelers to write down the expected responses to these prompts.
Prompts may also be collected from user-submitted input to ChatGPT. Remember from further above that when you use the ChatGPT service directly you implicitly provide permission to "improve the service"? That's your contribution to OpenAI's fine-tuning right there. Thank you. Much appreciated.
However, this type of supervised fine-tuning is very inefficient and presents a Hercules task with a number of issues:
-
The selection of prompts for the data set is finite and arbitrary. Human language, on the other side, is infinite. No matter how many prompts you pick for training, they will still present only a tiny, arbitrarily selected subset of the overall language universe.
-
Both the selection of prompts and the carefully crafted human responses are heavily biased. Most prompts do not have a single, distinct correct answer. Hence, the standard for what a correct response looks like will strongly depend on the group of human labelers and researchers creating the data set.
-
Manually crafting proper responses and conducting some measure of quality control to review and compile everything is very labor intensive, expensive and slow. As such, the process does not scale well. Given that in machine learning the quality of a model typically increases with the size of the data source, not being able to scale presents a significant drawback.
Despite these short-comings, the supervised fine-tuning already leads to an astonishing quality improvement compared to the bare pre-trained model. The model now has learned to follow instructions and have a conversation.
But there's more.
Reinforcement Learning with Human Feedback
Next, researchers apply proven concepts and ideas from reinforcement learning. Remember AlphaGo, the DeepMind computer program beating the best human player at Go? Yep, that's reinforcement learning.
Reward model
Again, a number of prompts are selected but this time they are fed into the already supervised fine-tuned model. The model then generates 4-9 different possible outputs which are then manually ranked by human labelers in terms of their suitability to serve as a proper response.
Practically speaking, this again is a form of supervised learning, as humans provide feedback to further train the algorithm. One immediate thought thus might be, isn't this approach then again bound by the same constraints as the prior step? Yes, but not really.
First, it's much easier and faster for a human to rank different responses than to write their own responses. Therefore, this kind of human feedback scales much better and results in a 10 times bigger data set than the data set curated in the prior step.
Second, the human rankings are used to train a new, separate model whose purpose is not to produce a response but to assess the quality of a response. Called the reward model, this new model can then be used by the algorithm to further train itself. Simply brilliant, isn't it!? Scalability ... checked.
How exactly does this work?
PPO reinforcement learning
Enter Proximal Policy Optimization. PPO is a reinforcement learning algorithm to optimize outcomes against a reward model. Initiated with the values of the supervised fine-tuned model, the PPO model continuously generates outputs and asks the reward model to calculate a reward for this output. The reward is then used to further update and improve the PPO model.
Put together, this technique is called Reinforcement Learning with Human Feedback or RLHF. And the result of this process is now an instruction-following model that is capable of dialog and reasoning.
Fine-tuned LLMs
ChatGPT is not the only kid on the block. Driven by the recent success of ChatGPT, a quickly growing number of fine-tuned models are mushrooming online, most of which are based on Facebook's LLaMa foundation model:
- Gpt4all which comes with a neat installer to install your own ChatGPT desktop app
- H2OGPT
- FastChat
- Vicuna
There is also a growing number of universities who joined the race to support academic research:
- Stanford's Alpaca and later Alpaca-LoRA
- Berkeley's Koala
Microsoft apparently watched too much Marvel and has now launched Iron Man's JARVIS -- an intelligent agent that can combine text, vision and speech. Fascinating. Here comes the future.
Another one that I found worth mentioning is LAION's Open Assistant, an attempt to fully open source LLM technology. Definitely interesting to watch how this unfolds.
Fine-tuning becomes easier and cheaper
Much of the mush-rooming has been made possible by recent algorithmic improvements such as Lora which allow to drastically decrease the size of the model in fine-tuning, allowing to fine-tune models even on a laptop. Incredible.
LoRA uses low-rank factorizations to drastically (by a factor of 10,000) reduce the size of the matrices that need to be updated during training. Foundation models can now be fine-tuned at a fraction of the cost and time. People are now able to personalize a language model in a few hours on consumer hardware, causing Google employees to cry out: We Have No Moat.
Given this kind of progress, I'm thinking that by 2030 we probably run a 100 billion parameter AI model on a toaster. LOL
Dolly -- Again the first
A common problem of most of these fine-tuned LLMs though is that their licensing prohibits commercial usage. Bummer!
It's only recently that Databricks released a new fine-tuned data set, meaningfully called Dolly, that fully supports commercial usage. Yippie.
Databricks went through the above cumbersome and labor-intensive process of manually creating a human generated dataset, about 15k instruction-response-pairs in size, crowd-sourced among 50 thousand of Databricks' own employees. This data set was then used to fine-tune EleutherAI's Pythia model.
Models a la carte
Dolly 2.0 is available as a 3, 6 and 12 billion parameter model. All nicely served on Huggingface. The higher the number of parameters, i.e. weights in the underlying neural network, the more nuanced and adaptive, in short the more powerful, the model.
Setting up your own ChatGPT locally
Now that we better understand how ChatGPT works, let me go back to our objective of building our own ChatGPT that is not only as smart as the real ChatGPT but that can also run locally, can be used commercially, and can connect to our own personal data sources.
With Dolly we now have a fine-tuned LLM that supports all of this. So let's roll-up our sleeves and take a look.
Load a fine-tuned model
The easiest way to download Dolly is to clone the respective repository at Huggingface. I'm using the 12 billion parameter version to be able to obtain the best possible results.
Once downloaded, you can prepare running your own LLM with only a few lines of Python code:
1import torch
2from instruct_pipeline import InstructionTextGenerationPipeline
3from transformers import AutoModelForCausalLM, AutoTokenizer
4
5tokenizer = AutoTokenizer.from_pretrained('dolly-v2-12b', padding_side='left')
6
7model = AutoModelForCausalLM.from_pretrained('dolly-v2-12b', device_map='auto', torch_dtype=torch.bfloat16)
8
9generate_text = InstructionTextGenerationPipeline(model=model, tokenizer=tokenizer, return_full_text=True, task='text-generation')
To make this work though you will need to download the instruct_pipeline code file from Huggingface. Alternatively, you could also not download the file and instead go with the trust_remote_code = True option which I did not want to do.
Generating a response to an arbitrary prompt is then as simple as:
1prompt = "Explain to me the difference between nuclear fission and fusion."
2
3response = generate_text(prompt)
4
5print(response)
1Nuclear fission and fusion are both methods that can be used to release energy. Nuclear fission is the method that a nuclear bomb uses to release a large amount of energy by splitting the nucleus of an atom. Fusion, on the other hand, is a method that aims to create a more manageable amount of energy by combining two small atomic nuclei together. Currently, the only method of creating fusion on a commercial level is through nuclear fission.
At first, I tried running the above prompt on my 16 GB RAM MacBook and failed. Apparently, 16 GB of RAM doesn't cut it for the 12 billion Dolly model. So, I moved over to my older MacMini which is equipped with a slightly more generous 64 GB of memory.
To my surprise, the query takes almost 8 minutes to complete. Likely due to that pathetic, antique Intel chip. Apple Silicon, where are you!?
This type of performance and waiting time is too tiring. I decide to move the test over to an Azure server.
Running locally in the cloud
Among the large choices available I select the M128s with 128 vCPUs and 2T RAM for $1.33 per hour, running on Debian Bullseye:

The same prompt now takes only around 80 seconds to respond to. Still not the fastest but definitely an improvement over my MacMini.
1$ python3 dolly.py
2
3Explain to me the difference between nuclear fission and fusion.
4
5Nuclear fission and fusion are both methods that can be used to extract energy from nuclear material. Nuclear fission, also known as fission energy, involves splitting the nucleus of an atom to release concentrated amounts of energy. In contrast, fusion involves heating up a small amount of nuclear material to very high temperatures, causing a reaction that produces more mass than either of the original inputs. As a result of this fusion reaction, more mass than what was started with is released. Both methods of nuclear energy production are being researched, but fusion has been identified as having the potential to be a more sustainable and lower carbon emission energy source than fission.
Bored waiting for another chat response, I start thinking: what about if the whole model was loaded into memory? That should help to speed things further up, shouldn't it?
I quickly setup a 1T RAM drive, and copy the whole code with model onto this RAM drive and run it from there. One reason why I had opted for the M128s in the first place was that it comes with 2T of RAM. So this should work well for my needs. So I thought.
1sudo mkdir -p /mnt/ram
2sudo mount -t ramfs -o size=1000g ramfs /mnt/ram
3sudo chown -R matt:matt /mnt/ram
So how long does model inference take now if everything is loaded into and run in memory?
Still a whopping 60+ seconds! Bummer. That's a bit of a surprise. Hardly any performance gain there.
Actually, running the same prompt a couple of times generates a different response each time and execution time depends, more than on anything else, on the length of the returned response. So, performance tuning is definitely something to be further investigated. Some other time.
For now, I'm good. I'm running the LLM on my own server, completely stand-alone and disconnected from OpenAI or any other online service. The aforementioned issues of data privacy and usage-dependent cost have thus been successfully addressed.
Performance is still not great, but hey, it's just a POC. So all good for now to proceed.
But what about the lack of domain expertise?
Connect to your own data sources
Enter Langchain: "LangChain is a framework for developing applications powered by language models." It allows to chain or connect different NLP components to achieve a particular objective.
For example, you can connect additional text components to your prompt. This additional input to your prompt can be thought of as some additional context that you want the model to be aware of.
Let's see how this look in practice.
I refactor above code and put the tokenizer and pre-trained model into a new function called text_generation_pipeline:
1
2def text_generation_pipeline():
3
4 tokenizer = AutoTokenizer.from_pretrained('dolly-v2-12b', padding_side='left')
5
6 model = AutoModelForCausalLM.from_pretrained('dolly-v2-12b', device_map='auto', torch_dtype=torch.bfloat16)
7
8 return InstructionTextGenerationPipeline(model=model, tokenizer=tokenizer, return_full_text=True, task='text-generation')
This function now serves to represent a local LLM in our chain. Langchain offers a number of built-in integrations to many of the currently popular LLMs, online. But I don't want to connect to an online LLM. I want it to run stand-alone.
And instead of a simple string prompt let's use a PromptTemplate which allows to easily construct more complex prompts. A bit of an overkill for this simple example, but will come in handy later.
We can now generate a response based on a user's instruction with the following code:
1from langchain import PromptTemplate, LLMChain
2from langchain.llms import HuggingFacePipeline
3
4llm = HuggingFacePipeline(pipeline=text_generation_pipeline())
5
6input_variables = ['instruction']
7template = "{instruction}"
8prompt = PromptTemplate(input_variables=input_variables, template=template)
9
10llm_chain = LLMChain(llm=llm, prompt=prompt)
11response = llm_chain.predict(instruction=instruction)
This pretty much gets us the same result as earlier but is now nicely utilizing the Langchain structure which can be easily expanded.
Adding context to your prompt
Instead of just feeding a single input_variable into the model, we can add another input_variable which I call context. And, we also add this new variable into our template. The rest is the same.
1from langchain import PromptTemplate, LLMChain
2from langchain.llms import HuggingFacePipeline
3
4llm = HuggingFacePipeline(pipeline=text_generation_pipeline())
5
6input_variables = ['instruction', 'context']
7template = "{context}\n{instruction}"
8prompt = PromptTemplate(input_variables=input_variables, template=template)
9
10llm_chain = LLMChain(llm=llm, prompt=prompt)
11response = llm_chain.predict(instruction=instruction, context=context)
With this simple design we can now inject additional, user- or domain-specific context into a prompt. For example:
1CONTEXT: Matt Lind is a technology professional from Germany living in China.
2
3INSTRUCTION: What country does Matt Lind come from?
4
5RESPONSE: Germany
I slightly change the question, to check whether my ChatGPT is able to correctly detect what I am actually asking about.
1CONTEXT: Matt Lind is a technology professional from Germany living in China.
2
3INSTRUCTION: What country does Matt Lind live in?
4
5RESPONSE: Matt Lind lives in China
Cool! While the original pre-training and fine-tuning taught the model to deal with the structure of my question, the content for the response is taken from my additional input. That's exactly the kind of domain expertise injection that we were looking for.
So, is that it? Can we simply pass our whole domain expertise as context into our prompt?
No.
Limitations of context-injection via prompt
Extending the prompt is quite limited. Actually, if we just wanted to extend the prompt in every query we don't have to use Langchain in the first place. Since LLMs simply continue any given text piece, you could do the above using a vanilla LLM implementation without Langchain.
Extending the prompt, however, faces limitations. First, most current LLM implementations have a technical limit in terms of the number of tokens that can be passed into the model. For OpenAI. for example, the total number of tokens, specifically prompt and response tokens combined, is 4097:
Token Limits
Depending on the model used, requests can use up to 4097 tokens shared between prompt and completion. If your prompt is 4000 tokens, your completion can be 97 tokens at most. The limit is currently a technical limitation, but there are often creative ways to solve problems within the limit, e.g. condensing your prompt, breaking the text into smaller pieces, etc.
Second, it's very inefficient to inject the same context or domain knowledge with every single request again and again.
Third, the scale of the context or domain expertise that we want to inject may be huge and spread over different sources. Buried in company databases, Sharepoint libraries, documents, websites, etc.
What if we could compress all of our private or domain-specific information into a single local data source and then inject this data source into our model?
Vector data stores
Enter vector data stores. Vector data stores can be thought of as semantic databases that store information as numerical representations (vectors) and allow for convenient and fast semantic searches across that information.
Langchain already supports a range of vector data stores built-in. At first, I opted for Redis which I'm already familiar with for session management. However, since the required RediSearch module requires an Enterprise license I end up using Facebook's FAISS which is one of the easiest to get started with and thus ideal for testing.
To move on, I need a personal data source for testing. Something that's ideally not available publicly and has not been seen by ChatGPT during pre-training.
Talking to a PDF
But what do I use? Turns out this is harder than expected. There is not that much stuff sitting on my computer that's interesting to share and that I'm comfortable putting on a public blog.
Instead, I decide to run the test using an annual financial report downloaded from here.
After a brief scan of the document, I find the following passage on page 8:
Diversity and inclusion continues to be a core priority for every employee at Microsoft and is incorporated into our performance and career development approach.
and decide to try to query for this particular piece of content via the prompt:
1"What is a core priority for every employee at Microsoft?"
Since I got this text from a public server, I need to confirm that the contained text has not been part of the model's prior training already. Therefore, I first query the vanilla Dolly model without the chained report:
1PROMPT: What is a core priority for every employee at Microsoft?
2
3RESPONSE: Microsoft promises to continuously deliver shareholder value through the deployment of innovative technology solutions, the development of commercially successful products, and the hiring of world-class employees.
And because the model spits out a different creative response every time, I run the prompt a couple of times more just to check that "Diversity and Inclusion" are not mentioned, i.e. have not appeared in the corpus that was used for either pre-training or fine-tuning.
1PROMPT: What is a core priority for every employee at Microsoft?
2
3RESPONSE: Microsoft always puts its customers first. The customer is at the core of everything we do and we invest significantly in making our customers successful. We help our customers realize their vision through our product innovations and through the people who work here.
4
5RESPONSE: Being responsive to customer requests
Looks good. The responses from the vanilla model do not include the correct information that we're looking for. The model has likely not seen this document before.
Now, let's try to chain this PDF to our LLM.
We first load the content of the PDF and split it into smaller, more digestible chunks of text.
1loader = PyPDFLoader('2021_Annual_Report.pdf')
2documents = loader.load()
3text_splitter = CharacterTextSplitter(' ', chunk_size=200, chunk_overlap=0)
4chunks = text_splitter.split_documents(documents)
Then we add the chunks into a vector store. As I mentioned above, we'll use FAISS for its simplicity. For production use, there are many alternative options.
Langchain also allows to choose what embeddings to use to represent the text as vectors. Since I want my professional agent to run offline without an OpenAI API key, I choose the HuggingFaceEmbeddings.
1
2embeddings = HuggingFaceEmbeddings()
3vector_store = FAISS.from_documents(chunks, embeddings)
Now, we can search the vector store for our prompt via a semantic similarity search:
1similar_chunks = vector_store.similarity_search(query)
Text pieces that are recognized as semantically close to our query will be returned as chunks. We then simply feed those chunks as additional input_documents into our LLM chain:
1llm = HuggingFacePipeline(pipeline=text_generation_pipeline())
2chain = load_qa_chain(llm, chain_type="stuff")
3response = chain.run(input_documents=similar_chunks, question=query)
What do we get?
1PROMPT: What is a core priority for every employee at Microsoft?
2
3RESPONSE: Diversity and inclusion is a core priority for every employee at Microsoft. This is important to Microsoft because of the company's value in creating a more inclusive workplace and driving change in the communities where Microsoft operates. Diverse teams and companies are better able to solve complex problems and create innovative solutions.
Voila! The same LLM now responds with the desired answer: Diversity and inclusion
The 2nd and 3rd sentences in that response BTW did not exactly match the report. Dolly must have found those somewhere else, or, again, hallucinated.

Where does this go from here?
This is the moment when I have to think of the movie "Her". Do you remember the scene at the beginning when Theodore installs his new operating system and his new AI agent asks for permission to access his email and files?
Yep. We're almost there now. What seemed far utopia back then is starting to appear possible. With all its pros and cons.
Limitations
This simple POC demonstrates how powerful this technology can be. Once connected to your own data sources, this type of GPT-like agent becomes a search engine on steroids. Users will be able to use natural language, either by typing or by speaking, to retrieve any information they want. With high accuracy and no end-user training required.
At the same time though, running this test also taught me some of the current limitations of LLMs and GPT-like technology:
-
Model accuracy -- The Dolly model proved less powerful or less accurate than its famous OpenAI counterpart. Not all models are created equal. And model quality has a significant impact on the agent's ability to produce high quality responses.
-
Compute power -- The fact that training LLM takes a huge amount of compute power is well known. But with the recent humungous sizes of LLMs nowadays, even inference (i.e. simply pushing a query through the trained model) is becoming a very memory- and compute-intensive undertaking.
-
Hallucination -- LLMs are non-deterministic. It's very difficult, if not impossible, to trace and reconstruct why a certain query led to a certain response. The model may combine inputs and randomly extrapolate non-sense.
While the first two limitations are likely being addressed by the continuous evolution of hardware and algorithmic enhancements in the next couple of years, the third presents a real challenge and an unsolved problem. One potential option to address hallucination is Prompt Engineering which I likely explore next in a different post.
Thank you for reading. Feel free to reach out with any comments or questions.
Happy coding!
Further readings
- How ChatGPT actually works
- List of Open Sourced Fine-Tuned Large Language Models (LLM)
- A Survey of Large Language Models
- Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM
- LoRA: Low-Rank Adaptation of Large Language Models
- We Have No Moat
- Langchain dolly-first-open-commercially-viable-instruction-tuned-llm
Similar talk to PDF blog posts: