Reading all of Wikipedia in 6 seconds: how to utilize multiple cores to process very large text files
I was about to do some basic natural language processing (NLP) task on a large text file: create a dictionary of unique words and count how many times each word occurs. Easy peasy. This should only take me a minute. So I thought. While coding did not take more than 2 zips of coffee, I needed to wait almost an hour for the task to complete. That was unacceptable. There must be a way to accelerate this process.
So I detoured, digging into parallel processing with multi-core computers. Along the way, I learned about semaphores, mutexes, pipes, and parallel hash tables. I knew I was cracking the nut with a sledgehammer. But hey, data files are only getting bigger. Remember anyone complaining “the data source is too big for our model!”? Me neither.

A friend asked me for help to assess a new algorithm for building word embeddings. Remember those numerical representations of words that allow you to do arithmetic calculations such as the (in)famous
1King - Man + Woman = Queen
equation? In a typical machine learning manner, he emphasized that we would need a very large text corpus for building and training the model. Otherwise, the algorithm wouldn’t work.
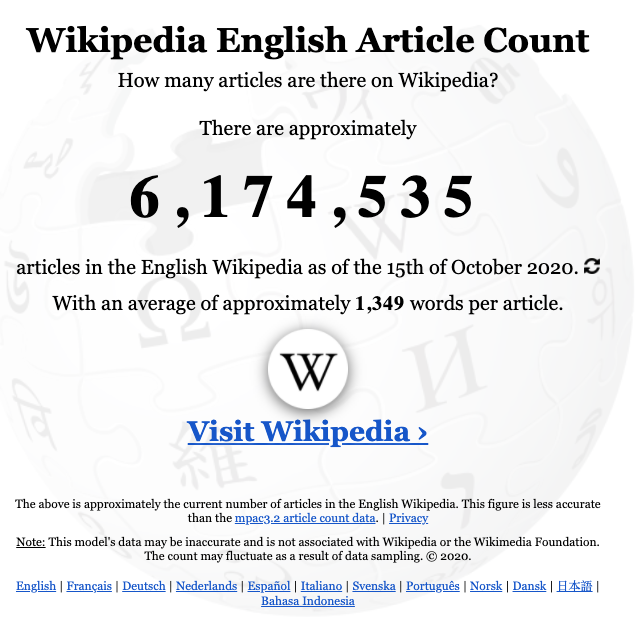
So, off I go to look for freely available large text corpora. One of the first potential sources that come to my mind is ... Wikipedia. As of October 2020, the English Wikipedia text spans more than 6 million articles. With an average of 1,324 words per article the whole corpus should provide us with 8 billion words. That seemed like a good start.
Reading large Wikipedia files
Regular backups are available at dumps.wikimedia.org, and the latest dumps of the English site can be downloaded here. Simply look for a file enwiki-latest-pages-articles.xml.bz2 which includes all current articles.
Naturally, these files are not small. The current version of the English Wikipedia dump file is a whopping 17.7 GB, compressed. One of the reasons for the enormous file size is that all dump files come in a clumsy XML format which carries a lot of extra baggage.
I download the version dated October 2, 2020. Since I’m interested in a plain text corpus, I need to strip off the XML markup and all the metadata that is included. Fortunately, there are tools that convert the files in a breeze, such as Building a Wikipedia Text Corpus for Natural Language Processing or WP2TXT.
Creating a dictionary from a text corpus
After conversion to plain text, the dump file of the English Wikipedia still weighs a staggering 17.3 GB. (After decompression, the original dump file exploded to 78 GB of XML which then get stripped down to 17 GB.) I call it enwiki.txt. This is the file that I am going to work on.
My first task is to build a dictionary of its unique words and count their respective occurrences. The tool I’m using to create the dictionary is Python, the de facto weapon of choice nowadays for many machine learning practitioners, data scientists, and anyone else who wants to get stuff done quickly.
Processing with Python
Python is amazing. The language empowers a developer to achieve complex tasks with little code. Creating a dictionary from a text corpus requires only a few lines:
1import datetime
2
3start_time = datetime.datetime.now()
4
5dic = {}
6for word in open('corpus/corpus.txt').read().split():
7 if word in dic:
8 dic[word] += 1
9 else:
10 dic[word] = 1
11
12top = sorted(dic, key=dic.get, reverse=True)[:10]
13
14print("Execution time: %.0f seconds" % (datetime.datetime.now() - start_time).total_seconds())
15
16print("Number of words in the dictionary: %d" % len(dic))
17
18print("Top 10 words:")
19
20for word in top:
21 print(word,dic[word])
Yes, this is elementary school syntax. Hold on. We’re just getting started. If you’re a devoted Pythonista you must know at least 27.5 other ways to do this. If you want to highlight any method in particular, please leave a comment below.
Running this script on my computer takes 3,430 seconds to complete. That’s me waiting for more than 53 mins. Or almost one hour. Just to tell me the following:
1Execution time: 3,430 seconds
2
3Number of words in the dictionary: 9,969,783
4
5Top 10 words:
6the 187,815,597
7of 94,989,314
8and 79,019,333
9in 76,509,632
10to 52,986,068
11was 30,276,734
12is 23,444,605
13for 23,133,442
14on 22,621,322
15as 22,363,717
Huh. I’m going to end up with a caffeine addiction if I don’t speed this up. Come on, Python. You can do better than that.
The simple split() method doesn’t cut it. And, I want to include some pre-processing such as converting all words to lower case. So I plugin the following method next, using Python’s counter function.
1from collections import Counter
2from itertools import chain
3from string import punctuation
4import datetime
5
6def count_words_in_file(filename):
7 with open(filename) as f:
8 linewords = (line.translate(punctuation).lower().split() for line in f)
9 return Counter(chain.from_iterable(linewords))
10
11
12start_time = datetime.datetime.now()
13
14dic = count_words_in_file('corpus/enwiki_short.txt')
15top = dic.most_common(10)
16
17print("Execution time: %.0f seconds" % (datetime.datetime.now() - start_time).total_seconds())
18
19print("Number of words in the dictionary: %d" % len(dic))
20
21print("Top 10 words:")
22
23for t in top:
24 print(t)
That’s a few libraries to import, but it’s concise, elegant, and even covers the pre-processing. Nice. And more importantly, this method performs better, taking only 1,402 seconds or about 23+ minutes on my computer to complete. Yeah. This saves me half an hour.
1Execution time: 1,402 seconds
2
3Number of words in the dictionary: 10,148,725
4
5Top 10 words:
6('the', 187,814,291)
7('of', 94,986,720)
8('and', 79,017,578)
9('in', 76,500,162)
10('to', 52,983,623)
11('was', 30,276,660)
12('is', 23,444,109)
13('for', 23,132,718)
14('on', 22,619,230)
15('as', 22,363,452)
Both methods return the same top 10 words. The exact token counts yet differ because they use different word boundaries.
I’m grateful for the additional half an hour that my life just gained. I’m celebrating for a few seconds, then my mind wanders off. Come on. It’s 2020. Almost every home computer comes with multiple cores, running at >3 Ghz. The Mac Mini I’m using to write this blog on boasts 6 cores. With that much computing power is it not possible to speed up the processing of large text files? And how can I effectively use all cores and process the file in parallel?
Questions demand answers. I decide to do some investigation into multiprocessing and multithreading. I want to assess how any such techniques could help me to process the Wikipedia file faster.
Sequential processing with C
I start my investigation by developing a simple C program that processes the text corpus on a single core, sequentially.
Writing C code is clearly not as efficient and elegant as coding in Python. The idea of the sledgehammer begins to form. But hey, for this kind of operation I need a scalpel, not a kitchen knife. And I just love the power and precision of the C language.
I break down the algorithm for creating the dictionary into 4 main steps:
- Map the corpus file to memory
- Read the corpus word by word
- Deduplicate all words
- Sort the words by count in descending order
Wow. Just mapping out my to-do list already takes more lines of writing than coding the whole piece in Python. This better works.
1. Map the corpus file to memory
Given the monstrous size of Wikipedia dump files, I want to ensure they can be read on computers that do not have sufficient memory to load the complete file at once. Therefore, I use mmap to map the physical file into memory. The loading into memory happens dynamically and the operating system helps to cache pages which further improves performance.
1void *map_shared_file(const char *fname, size_t *fsize){
2
3 struct stat fstat;
4
5 if (stat(fname, &fstat) == -1) {perror("[STAT] Error getting file stats! ABORT. ");exit(1);}
6
7 *fsize = fstat.st_size;
8
9 int fd = open(fname, O_RDONLY);
10 if (fd == -1) {perror("[OPEN] Error opening file for shared use! ABORT. ");exit(1);}
11
12 char *mem = mmap((void*)0, *fsize, PROT_READ, MAP_SHARED, fd, 0);
13
14 if (mem == (void*)(-1)) {perror("[MMAP] Error creating shared memory for file reading! ABORT. ");exit(1);}
15
16 if (close(fd)==-1) {perror("[CLOSE] Error closing mapped file! ABORT. ");exit(1);}
17
18 return mem;
19
20}
Using mmap is simple and straight forward. I create the above function map_shared_file() to do and hide all the usual error handling. The function returns a pointer which allows reading the file simply by accessing the pointer. The function also returns the file size of the corpus which I will need later.
BTW: I also tested loading the corpus file into memory. Surprisingly, this did not result in any measurable performance improvement. On the contrary, in some scenarios loading the file into memory was somewhat slower than mapping the file.
2. Read the corpus word by word
To process the corpus word by word, I first introduce an object for representing a word that I can use throughout the program. I call it the corpus_token_t:
1// basic structure to represent a 'word/token' that exists in the corpus
2typedef struct corpus_token_t{
3 size_t off; // offset of 1st occurrence in corpus
4 int len; // length of the token, not null-terminated
5 size_t count; // counter for how many times this token is found
6} corpus_token_t;
If you have worked on NLP you’re familiar with the token terminology. It’s neither a coin nor a password. And has no relationship to cryptocurrencies. In some languages, such as Chinese or other Asian languages, the most basic element of a sentence or a text is not a word but a character. A token represents an element of the written language: either a single character or a series of characters, i.e. a word.
To maximize performance my corpus_token_t object does not include a string or the actual character representation of the token. (Yes, I know. C doesn’t have a string in the first place. But you know what I mean.) Instead, I only store the offset of the first occurrence of this token in the corpus. Plus its length and a counter for how many times this token appeared in the corpus.
Now, I can stroll along and read the file. But wait. What’s that? I see 2 bumps in this walk in the park: multi-byte sequences and word boundaries.
Multi-byte sequences
I want to be able to read Wikipedia dumps (or any other text files for that matter) of any language. Therefore, I can’t read the file simply char by char because in many languages a single ‘letter’, or character, uses more than a single byte char.
UTF8 has become a de facto standard in the digital world. Unfortunately, in UTF8 there is no fixed character length. Characters may range in size from 1 to 4 bytes which makes handling UTF8 in C a bit of a pain.
Fortunately, there are some small libraries to come to the rescue. Jeff Bezanson’s early groundwork for UTF8 processing called cutef8, for example. I grab his macro for identifying whether a char is UTF8...
1#define IS_UTF8(c) (((c)&0xC0)!=0x80)
... and pump up his original u8_memchr function to create the following get_next_token function to read a text segment of given length token by token:
1bool USE_SINGLE_CHARS_AS_TOKENS = false; // set to 'true' for Asian languages
2
3corpus_token_t get_next_token(char *corpus, size_t *idx, size_t end){
4
5 corpus_token_t tok;
6 size_t start_idx = *idx;
7
8 // move IDX forward in case it points INSIDE of a multibyte character
9 while (!IS_UTF8(corpus[*idx]) && (*idx < end) && corpus[*idx]) (*idx)++;
10
11 // move IDX gradually forward
12 while (*idx<end && *idx - start_idx<MAX_TOKEN_STRING_LENGTH && corpus[*idx] ){
13
14 uint32_t u8_char_code = 0;
15 int u8_char_size = 0;
16
17 do {
18 u8_char_code <<= 6;
19 u8_char_code += (unsigned char)corpus[*idx];
20 u8_char_size++;
21 (*idx)++;
22 } while (*idx<end && corpus[*idx] && !IS_UTF8(corpus[*idx]));
23
24 u8_char_code -= UTF8_OFFSETS[u8_char_size-1];
25
26 // 3 exit conditions: (1) multi-byte character, (2) end of text, (3) token delimiter
27 bool is_del = is_token_delimiter(u8_char_code);
28 if (is_del || *idx==end || (USE_SINGLE_CHARS_AS_TOKENS && u8_char_size>1)) {
29 tok.len = is_del ? (int)(*idx - start_idx - u8_char_size) : (int)(*idx - start_idx);
30 tok.off = start_idx;
31 tok.count = 1;
32 return tok;
33 }
34
35 }
36
37 // if no token was found, return empty token reference
38 tok.len = 0;
39 tok.off = 0;
40 tok.count = 0;
41
42 return tok;
43}
Good. This takes care of bump #1. Moving on.
Word boundaries
What constitutes a word? In most Western languages one obvious answer is a whitespace between two characters. Sure. But there are plenty of other characters and cases to consider. I wrap all such characters into a function is_token delimiter. Whenever a token delimiter is read, the end, or boundary, of a token has been reached.
1bool is_token_delimiter(u_int32_t utf_code){
2
3 return (bool) (
4 utf_code == 32 || // " " space
5
6 utf_code == 9 || // " " tab
7 utf_code == 10 || // "\n" linefeed
8 utf_code == 13 || // "" carriage return
9 utf_code == 33 || // '!'
10 utf_code == 34 || // '"'
11 utf_code == 35 || // '#'
12 utf_code == 39 || // '''
13 utf_code == 40 || // '('
14 utf_code == 41 || // ')'
15 utf_code == 42 || // '*'
16 utf_code == 43 || // '+'
17 utf_code == 44 || // ','
18 utf_code == 46 || // '.'
19 utf_code == 47 || // '/'
20 utf_code == 58 || // ':'
21 utf_code == 59 || // ';'
22 utf_code == 60 || // '<'
23 utf_code == 61 || // '='
24 utf_code == 62 || // '>'
25 utf_code == 63 || // '?'
26 utf_code == 91 || // '['
27 utf_code == 92 || // '\'
28 utf_code == 93 || // ']'
29 utf_code == 95 || // '_'
30 utf_code == 123 || // '{'
31 utf_code == 124 || // '|'
32 utf_code == 125 || // '}'
33
34 utf_code == 8212 || // '—''
35 utf_code == 8216 || // '‘'
36 utf_code == 8217 || // '’'
37 utf_code == 8220 || // '“'
38 utf_code == 8221 || // '”'
39
40 utf_code == 12289 || // u8"、"
41 utf_code == 12290 || // u8"。"
42
43 utf_code == 65281 || // u8"!"
44 utf_code == 65288 || // u8"("
45 utf_code == 65289 || // u8")"
46 utf_code == 65292 || // u8","
47
48 utf_code == 65306 || // u8":"
49 utf_code == 65307 || // u8";"
50 utf_code == 65311 || // u8"?"
51
52 (utf_code >= 917600 && utf_code <= 917699) ||
53 (utf_code >= 1113000 && utf_code <= 1113100)
54
55 );
56
57}
The definition of token delimiters impacts the number of tokens put into the dictionary and their respective counts. If the raw text version of the Wikipedia dump file does not include punctuation then you don’t need this many token delimiters because most of these characters have already been removed during XML to TXT conversion.
Equipped with these two functions I can now loop through the file and pick up all its tokens as follows:
1char CORPUS_FILE_NAME[100] = "enwiki.txt"
2
3size_t corpus_fsize;
4
5char *corpus = map_shared_file(CORPUS_FILE_NAME, &corpus_fsize);
6
7size_t pos = 0;
8size_t end = corpus_fsize;
9
10corpus_token_t tok;
11
12while(pos < end){
13 tok = get_next_token(corpus, pos, end);
14
15 if (tok.len>0) {
16
17 // do something with this token....
18
19 }
20
21}
Straight forward and painless. So far, so good. What’s next? What do I do with the tokens read from the corpus?
3. Deduplicate all words
A dictionary is a list of all the unique words, or tokens, in a text. Therefore, I need to deduplicate the tokens. And do so at the speed of light.
Enter hash tables. One of the most efficient tools for deduplication and quick lookups is a hash table. The string of a token shall serve as my hash key. I’m sketching down the main steps I need to implement:
- Create the hash table
- Hash a string
- Compare tokens
- Insert a token into the hash table
Create the hash table
The hash table itself is nothing but an array of corpus_token_t objects. Not a fan of dynamically resized arrays, I wonder about its size. There is no agreed definition of the ideal or best size of a hash table. Some argue its load factor – the share of hash table entries, or buckets, that are filled – should not exceed 70%. Sounds like a reasonable metric to start from.
But wait. The size of the hash table depends on the size of the dictionary, which in return depends on the size of the corpus text. Would it not be ideal to link the size of the hash table directly to … say … corpus file size? After all, if the table is too big, I’ll be wasting lots of memory. If it’s too small, I’ll have lots of hash ‘misses’ which will slow down performance.
I decide to sacrifice a few bits for the sake of performance, and come up with the following, somewhat arbitrary, formula that defines hash size based on file size:
1MAX_HASH_LENGTH = 30000 * pow(2,log10(corpus_fsize));
2// MAX_HASH_LENGTH = 13727587;
3// MAX_HASH_LENGTH = 18303449;
4// MAX_HASH_LENGTH = 36606883;
5// MAX_HASH_LENGTH = 53150323;
6// MAX_HASH_LENGTH = 80000023;
7
8corpus_token_t *tok_htab = calloc(MAX_HASH_SIZE, sizeof(corpus_token_t));
The function includes, as comments, some of the fixed sizes that I used. They’re all prime numbers which arguably make better hashes. And if you wonder how do I get a prime number above, say, 50 million? No, I didn’t calculate them. I used this online tool to simply look them up.
Hash a string
Next, I need to hash each token to obtain a unique code. Remember that our corpus_token_t object does not include the actual character representation (aka string) of this token?
1void get_token_string(corpus_token_t tok, char *str, char *corpus){
2
3 memcpy(str, corpus + tok.off, tok.len);
4 memset(str + tok.len, '\0', 1);
5
6 // convert to lower case
7 char *p = str;
8 while ((*p = tolower(*p))) ++p;
9
10 return;
11}
I first need to obtain the string before I can create a hash. I also convert all tokens to lowercase to more efficiently utilize the hash table. And for most NLP tasks the case of a word is insignificant.
1size_t get_token_hash(corpus_token_t tok, char *corpus){
2
3 // create a character representation of the token
4 char tok_str[MAX_TOKEN_SIZE+1];
5 get_token_string(tok, tok_str, corpus);
6
7 // hash the token string
8
9 char *str = tok_str;
10
11 size_t hash = 5381;
12
13 int c;
14
15 while ((c = *str++)) hash = ((hash << 5) + hash) ^ c; // hash * 33 XOR c
16
17 return hash % MAX_HASH_SIZE;
18
19}
For the actual hashing, I use Daniel J. Bernstein’s DJB2 hash function which is simple and works well for strings. Feel free to try others.
Compare tokens
When I insert a token into the hash table, I need to check for potential collisions. Therefore, I need a comparison function to assess whether two tokens are equal.
1// compare two integers and return the smaller one
2#define MIN_OF_TWO(a,b) ({ __typeof__ (a) _a = (a); __typeof__ (b) _b = (b); _a < _b ? _a : _b; })
3
4int compare_corpus_tokens(const corpus_token_t *tok1, const corpus_token_t *tok2, const char *corpus){
5
6 int len1 = (*tok1).len;
7 int len2 = (*tok2).len;
8
9 int len = MIN_OF_TWO(len1, len2);
10
11 const char *str1 = corpus + (*tok1).off;
12 const char *str2 = corpus + (*tok2).off;
13
14 int r = strncasecmp(str1, str2, len);
15
16 // both strings differ in the first 'len' chars
17 if (r!=0) return r;
18
19 // both strings are the same
20 if (len1 == len2) return 0;
21
22 // if both strings have a different length but share the first 'len' characters
23 // the shorter one is the smaller one
24
25 if (len1 < len2) return -1;
26
27 return 1;
28}
The above function does that efficiently using pointers only.
Insert a token into the hash table
At last, I insert the token into the hash table. If the token already exists, its counter will be incremented. If the assigned seat number on the hash table bus is taken already, let the token move on and find the next empty spot.
1void insert_token(corpus_token_t tok, corpus_token_t *htab, char *corpus){
2
3 size_t hidx = get_token_hash(tok, corpus);
4
5 while(1) {
6 // check if this bucket is empty
7 if (htab[hidx].len >0) {
8
9 // if the same token already exists in the hash table increment its counter
10 if (compare_corpus_tokens(&tok, htab + hidx, corpus) == 0) {
11 htab[hidx].count += tok.count;
12 return;
13
14 }
15 // otherwise move forward to the next bucket
16 else {
17 hidx++;
18 hidx %= MAX_HASH_SIZE;
19 }
20
21 } else {
22 // if this token's bucket was empty (i.e. first time) add it into the hash table
23 htab[hidx] = tok;
24 return;
25 }
26
27 }
28
29}
Note to self: The function does not check whether the hash table is large enough to fit all tokens. In fact, if there were more tokens to put in the dictionary than there are buckets in the hash table the loop would run infinitely. @todo
After all tokens are placed, the number of filled buckets tells me the number of unique tokens in the dictionary.
1size_t get_htab_token_count(corpus_token_t *htab){
2
3 size_t count = 0;
4
5 for (size_t i=0; i<MAX_HASH_LENGTH; i++)
6 if (htab[i].len>0) count++;
7
8 return count;
9}
4. Sort the words by count in descending order
Almost there. I have read and deduplicated all tokens, and popped them into a gargantuan, sparsely populated hash table. I also calculated the word count. But how do I sort a hash table?
You don’t. Instead, I first copy all unique tokens into a more compact representation: an array of tokens, a.k.a. the dictionary.
1corpus_token_t *create_dictionary(corpus_token_t *htab, char *corpus, size_t dict_tok_count, size_t *corpus_tok_count){
2
3 *corpus_tok_count = 0;
4
5 corpus_token_t *dict = calloc(dict_tok_count, sizeof(corpus_token_t));
6
7 size_t didx = 0;
8 for (size_t hidx=0; hidx<MAX_HASH_SIZE; hidx++){
9
10 if (htab[hidx].len>0) {
11 *corpus_tok_count += htab[hidx].count; // calc overall token count
12 dict[didx++] = htab[hidx]; // add token into dictionary
13 }
14
15 }
16
17 assert(didx == dict_tok_count);
18
19 return dict;
20}
The dictionary can then be easily sorted using a standard qsort algorithm.
1int compare_token_counters(const void *a, const void *b){
2
3 size_t freq_a = (*(corpus_token_t*)a).count;
4 size_t freq_b = (*(corpus_token_t*)b).count;
5
6 if (freq_a < freq_b) return 1;
7 if (freq_a > freq_b) return -1;
8 return 0;
9}
10
11
12void sort_dict(corpus_token_t *dict, size_t dict_tok_count){
13
14 qsort(dict, dict_tok_count, sizeof(corpus_token_t), compare_token_counters);
15
16}
That’s it. The moment of truth. I put all the above together: process the corpus, deduplicate tokens, count their occurrences, and sort the dictionary. And while I’m at it, I print out the top 10. Because I’m curious.
1void text2dict(void){
2
3 size_t corpus_fsize;
4 char *corpus = map_shared_file(CORPUS_FILE_NAME, &corpus_fsize);
5
6 MAX_HASH_SIZE = 100000 * pow(2,log10(corpus_fsize));
7
8 corpus_token_t *htab = create_token_hash table(corpus, corpus_fsize);
9
10 size_t dict_tok_count = 0;
11 size_t corpus_tok_count = 0;
12 corpus_token_t *dict = create_dictionary(htab, corpus, &dict_tok_count, &corpus_tok_count);
13
14 sort_dict(dict, dict_tok_count);
15
16 printf("# of tokens in corpus: [%'15lu]\n",corpus_tok_count);
17 printf("# of tokens in dict: [%'15lu]\n",dict_tok_count);
18
19
20 char tok_str[MAX_TOKEN_SIZE+1];
21 printf("Top 10:\n");
22 for (int i=0; i<10; i++) {
23 get_token_string(dict[i], tok_str, corpus);
24 printf("#%2d: %'12zu = %s\n",i+1,dict[i].count, tok_str);
25 }
26
27 // clean up
28 free(dict);
29 free(htab);
30 unmap_shared_memory(corpus, corpus_fsize);
31
32 return;
33}
I call the function text2dict which later turned into its own Github project. When I run the code I get the following result:
1Execution time: 756 seconds
2
3# of tokens in corpus: [ 2,796,219,305]
4# of tokens in dict: [ 9,925,231]
5
6Top 10:
7# 1: 187,816,162 = the
8# 2: 94,989,894 = of
9# 3: 79,019,494 = and
10# 4: 76,509,997 = in
11# 5: 52,986,487 = to
12# 6: 30,276,740 = was
13# 7: 23,445,023 = is
14# 8: 23,133,852 = for
15# 9: 22,621,486 = on
16#10: 22,363,826 = as
I’m getting pumped. Creating the dictionary sequentially via C takes 756 seconds, compared to 3,430 seconds from the first Python script, and 1,402 seconds from the second Python script. OMG. From now on, I will have to wait only 12 minutes each time I create the dictionary. Life is beautiful. Mine just extended another 10 minutes.
Parallel processing of text corpora
After a short moment of rejoicing, I recall my original objective: utilizing multiple cores. Alright. Let’s do this. I’m rolling up the sleeves. What hardware shall I use for the ride?
The hardware
The first machine is my Mac Mini. I ordered it with full specs: 6 cores, 64 GB RAM.
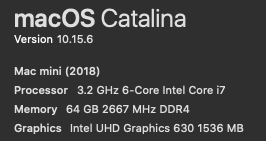
Can I trust the system info? Let me check the number of processing units via code:
1long nproc = sysconf(_SC_NPROCESSORS_ONLN);
The sysconf returns ... 12. Why the difference to the 6 cores that were reported by the system configuration window? Hyperthreading. 6 physical cores are presented as 12 virtual cores to the operating system.
Anyway. 6 or 12, not much of a difference, I’m thinking. If I want to investigate the scalability of parallel processing I better prepare a bit more firepower.
Utilizing Azure cloud servers
Enter Azure cloud servers. Microsoft’s Azure cloud offering is immense. You can order servers ranging from 1 to 416 cores. Yes, that’s four hundred sixteen cores. And not only does the ‘M416ms_v2’ come with a whopping 416 cores, but it also boasts 11 TB of RAM. What?! Yes, that’s not a typo. It’s a T, not a G. That’s more than 5 times my hard drive capacity ... in RAM.
Naturally, I want to include this beast in my testing and reach out to Azure support to get my hands on it. I am, however, advised that these servers require a corporate account. Why? Well, for one, I guess, because this machine runs at $95k per month. That’s “k” as in kilo. Oops. I know some people like burning money on Azure but this exceeds my budget just a tiny little bit.
Instead, I pick 2 other models. The first one is the “F64s_v2” with 64 cores and 128 GB RAM, running Debian Buster. I call it my “VM64”. I fire it up and print some system info from the console:
1$ lscpu
2
3Architecture: x86_64
4CPU op-mode(s): 32-bit, 64-bit
5Byte Order: Little Endian
6Address sizes: 46 bits physical, 48 bits virtual
7CPU(s): 64
8On-line CPU(s) list: 0-63
9Thread(s) per core: 2
10Core(s) per socket: 16
11Socket(s): 2
12NUMA node(s): 2
13Vendor ID: GenuineIntel
14CPU family: 6
15Model: 85
16Model name: Intel(R) Xeon(R) Platinum 8168 CPU @ 2.70GHz
17Stepping: 4
18CPU MHz: 2693.876
19BogoMIPS: 5387.75
20Virtualization: VT-x
21Hypervisor vendor: Microsoft
22Virtualization type: full
23L1d cache: 32K
24L1i cache: 32K
25L2 cache: 1024K
26L3 cache: 33792K
27NUMA node0 CPU(s): 0-31
28NUMA node1 CPU(s): 32-63
1$ free --giga
2
3 total used free shared buff/cache available
4Mem: 135 2 132 0 0 131
5Swap: 0 0 0
6SHELL
Yeah. Loading the Wikidump file into memory shouldn’t be a problem on this one.
The second cloud server is the “M128_s” with 128 cores and 2 TB RAM, also running Debian Buster. I call it my “VM128”.
1$ lscpu
2
3Architecture: x86_64
4CPU op-mode(s): 32-bit, 64-bit
5Byte Order: Little Endian
6Address sizes: 46 bits physical, 48 bits virtual
7CPU(s): 128
8On-line CPU(s) list: 0-127
9Thread(s) per core: 2
10Core(s) per socket: 16
11Socket(s): 4
12NUMA node(s): 4
13Vendor ID: GenuineIntel
14CPU family: 6
15Model: 85
16Model name: Intel(R) Xeon(R) Platinum 8280M CPU @ 2.70GHz
17Stepping: 7
18CPU MHz: 2693.670
19BogoMIPS: 5387.34
20Virtualization: VT-x
21Hypervisor vendor: Microsoft
22Virtualization type: full
23L1d cache: 32K
24L1i cache: 32K
25L2 cache: 1024K
26L3 cache: 39424K
27NUMA node0 CPU(s): 0-31
28NUMA node1 CPU(s): 32-63
29NUMA node2 CPU(s): 64-95
30NUMA node3 CPU(s): 96-127
1$ free --giga
2
3 total used free shared buff/cache available
4Mem: 2164 8 2155 0 0 2150
5Swap: 0 0 0
6SHELL
All set. Equipped with my cute Mac Mini and 2 potent cloud titans, I’m ready to take on the parallel processing of Wikipedia.
The basic design
I first assess each step of the overall algorithm from 2 angles: how does it impact performance, and how easy or difficult is it to run this step in parallel.
| Steps for creating dictionary | Impact on performance | Difficulty to parallelize |
|---|---|---|
| Reading corpus word by word | High | Low |
| Inserting words into hash table | High | Middle |
| Copying unique words into array | Low | Middle |
| Sorting array by word count | Low | High |
Good. Fortunately, the steps with a high impact on performance (reading the corpus, and inserting words into a hash table) are not difficult to parallelize. The steps with a low impact on performance (copying the words into an array and sorting the array) are not worthwhile spending a lot of extra time on. I just leave them as they are.
Reading text ‘in parallel’
To read the corpus in parallel, via multiple cores, I need to divide the text into multiple segments and have each core read a different segment. Therefore, I define an object range_t that represents a corpus segment by its start and end offset.
1// defines a segment via its first and last offset
2typedef struct range_t{
3 size_t from; // included
4 size_t to; // excluded
5} range_t;
Yes. Both from and to are offsets relative to the corpus text and not memory addresses or pointers.
Beware that while the
fromoffset is included in the range, i.e. it’s part of the segment, thetooffset is not.
Next, I divide the corpus into as many segments as there are cores, or processes, so that each process can work independently on a different text segment.
1range_t *create_segments(size_t total_size, long nsegs){
2
3 if (total_size < nsegs){perror("Error creating segments. ABORT");exit(1);}
4
5 range_t *segs = malloc(nsegs * sizeof(range_t));
6
7 size_t seg_size = total_size / nsegs;
8
9 for (long seg_idx=0; seg_idx<nsegs; seg_idx++){
10
11 // divide into equally-sized segments
12 segs[seg_idx].from = seg_idx * seg_size;
13 segs[seg_idx].to = segs[seg_idx].from + seg_size;
14
15 // always set the end of the last range to the end of the memory range
16 if (seg_idx == nsegs-1) segs[nsegs-1].to = total_size;
17
18 }
19
20 return segs;
21}
The problem with this approach is that I may mistakenly chop the file in the middle of a word, or possibly even in the middle of a character. Remember multi-byte characters in UTF8? Therefore, I adjust the split points between segments by simply moving each point forward to the beginning of the next token.
1range_t *create_corpus_segments(size_t corpus_size, long nsegs, char *corpus){
2
3 // first use default, i.e. divide into equally-sized segments
4 range_t *segs = create_segments(corpus_size, nsegs);
5
6 corpus_token_t tok;
7 size_t pos;
8
9 // move the split point to the right to the start of the next token
10 for (long seg_idx=0; seg_idx<nsegs; seg_idx++){
11
12 pos = segs[seg_idx].from;
13 tok = get_next_token(corpus, &pos, corpus_size);
14
15 // don't shift the 1st segment since it always starts at 0
16 if (seg_idx>0){
17 segs[seg_idx ].from = pos;
18 segs[seg_idx-1].to = segs[seg_idx].from;
19 }
20
21 }
22
23 return segs;
24}
Ok. So far, so good. To read the text in parallel I won’t need much else. I can reuse the other functions I built before. One critical piece though is missing.
Multiprocessing and multithreading
The 2 main technical options for a developer to implement parallel processing are multiprocessing and multithreading. Both execute multiple tasks simultaneously by spinning-off separate processes or threads that run independently of the main process.
For spinning-off multiple processes, I use the following general fork boilerplate code. All I need to add is my get_next_token function and tuck it into the loop.
1 int nproc = 6;
2
3 int pid;
4 for (int n=0; n<nproc; n++){
5
6 if ((pid = fork()) < 0) {perror("fork");exit(1);}
7 if (pid==0) {
8
9 // code that shall be executed by each child process
10
11 printf("Hello! I am process [%d].\n", getpid());
12
13 /// ...
14
15
16 _exit(0);
17 }
18
19 }
20
21 // wait for all child processes to finish
22 while(wait(NULL) != -1);
23
24 // parent process proceeds....
At the end of the function, I need to make the parent process wait until all child processes have exited. Not waiting for child processes to finish is a frequent source of errors. The wait command also allows me to bring the application logic back into a single process.
Beware that in the above
forkboilerplate codenprocrepresents the number of processes, not the number of processors. You could run more processes than there are actual processing units or cores.
Creating the dictionary in parallel
So. I finished reading the text, and feel tempted to pat myself on the back. After all, this was the heavy lifting, wasn’t it? Surely not. I just enjoyed my appetizer, and am moving on to the main course.
When multiple processes simultaneously make changes to the same variable (a.k.a. they need to write to the same shared memory), they may conflict, or overlap, with each other. So-called race conditions between processes will cause unpredictable results. Oh.
How to address race conditions between multiple tasks?
I can resolve the problem of race conditions in 3 ways:
- Avoid race conditions in the first place. Do not have multiple processes write to the same memory. Instead, each process writes to a different memory section, and sections are merged via a single process at the end.
- Synchronize memory access by having each process first lock the memory that it wants to write to. Other processes cannot access memory that is locked and need to wait until the locking process unlocks the memory again.
- Communicate between different processes in other ways than through memory sharing, such as sending messages or signals to each other. (Note to self: remember this nice tutorial on IPC called Beej’s Guide to Unix IPC.)
I choose to test and compare all three, via different technical implementations.
After some initial research, I jot down the following 4 methods for me to investigate:
- multiple hash tables (avoid),
- semaphores and mutexes (synchronize), and
- pipes (communicate).
In particular, I want to examine these 4 methods from 2 perspectives: performance and scalability.
| Parallel processing technique | Avoid simultaneous memory access | Synchronize simultaneous memory access | Communicate between processes (IPC) |
|---|---|---|---|
| Multiprocessing with separate hashes | ✓ | ||
| Multiprocessing with semaphores | ✓ | ||
| Multithreading with mutexes | ✓ | ||
| Multiprocessing with pipes for IPC | ✓ |
Methods for parallel text processing
Off I go to implement the four techniques one by one.
1. Multiprocessing with separate hashes
The easiest option to address race conditions is to avoid them. Instead of letting multiple processes write to the same memory, I can have each process write into its own separate hash table first and then merge the hash tables later. As easy as ABC.
I only need to make 3 modifications to the previous code:
- (A) create multiple hash tables,
- (B) make each process insert tokens into a different hash table, and
- (C) merge all hash tables into one at the end.
Create multiple hash tables
Before I create more than one hash table I need to assess the memory impact. The length of the hash table I used before ranges from 14 to 80 million buckets. If a single corpus_token_t element occupies up to 24 bytes, my little friend htab demands a humongous 1.8 GB of RAM. And that’s just for one. If I breed 12 of these guys, I’ll have to kiss goodbye to 22 GB of memory. Running 128 processes? 230 GB of memory. Ouch.
A few seconds of silence. ... “So what!” This is not my Sanyo MBC 550 anymore, coding Pascal on 128 KB of RAM. In only a few years, the average Mac or Surface laptop ships with at least several TB of RAM. Let’s face it. Memory is ‘cheap’, and the machines I use for this exercise surely can handle the magnitude. I give it a go.
1corpus_token_t *htabs = map_shared_memory(PROCESS_COUNT * MAX_HASH_LENGTH * sizeof(corpus_token_t));
This time, I cannot create the hash table simply via malloc. Instead, I define all of them as shared memory so that the parent process can later consolidate all individual tables into a single one.
Make each process insert tokens into a different hash table
Next, I need to slightly amend the function that inserts tokens into the hash table. I just add a process identifier pidx which I multiply by the hash size to determine the correct table for each process.
1void insert_token_pp(long pidx, corpus_token_t tok, corpus_token_t *htab, char *corpus){
2
3 size_t hidx = get_token_hash(tok, corpus);
4 size_t hidx_pp;
5
6 while(1) {
7
8 hidx_pp = (pidx * MAX_HASH_SIZE) + hidx; // <-- pick the hash table for this process
9
10 // check if this bucket is empty
11 if (htab[hidx_pp].len >0) {
12
13 // if the same token already exists in the hash table increment its counter
14 if (compare_corpus_tokens(&tok, htab + hidx_pp, corpus) == 0) {
15 htab[hidx_pp].count += tok.count;
16 return;
17
18 }
19 // otherwise move forward to the next bucket
20 else {
21 hidx++;
22 hidx %= MAX_HASH_SIZE;
23 }
24
25 } else {
26 // if this token's bucket was empty (i.e. first time) add it into the hash table
27 htab[hidx_pp] = tok;
28 return;
29 }
30
31 }
32
33}
BTW: I am adding
\_ppat the end of a function to signal this function is processed in parallel by multiple processes or threads.
Merge all hash tables into one
After all processes have finished reading their corpus segment and adding the respective tokens into their process-specific hash table, I need to consolidate all hash tables into one.
For merging hash tables I cannot simply copy over the tokens and sum up their counts. The hash index of a token in one table may differ from the hash index of the same token in another table. Why? Remember that in case of a collision, the insert function moves the hash index gradually forward until an empty bucket is found. Therefore, the hash index for any given token depends on the timing.
Specifically, it depends on what other tokens have been processed so far. I, therefore, merge the tables by simply using the previous insert_token function.
But how long is this going to take? Can I not parallelize the merging to further speed up the whole process? Sure. I divide the table into multiple segments, similar to what I did with the corpus text before. Then, I have each process merge tokens of a specific segment only. This ensures that there are no overlaps when a token is added. My merge function looks like this:
1corpus_token_t *merge_hashtables(char *corpus, corpus_token_t *htabs){
2
3 // create a new empty hash table that will hold the merged results of all processes' hash tables
4 corpus_token_t *htab = map_shared_memory(MAX_HASH_LENGTH * sizeof(corpus_token_t));
5
6 range_t *hsegs = create_segments(MAX_HASH_LENGTH, PROCESS_COUNT);
7
8 int pid;
9
10 for (long pidx=0; pidx<PROCESS_COUNT; pidx++){
11
12 if ((pid = fork()) < 0) {perror("fork");exit(1);}
13
14 if (pid==0){
15
16 for (size_t hidx=hsegs[pidx].from; hidx<hsegs[pidx].to; hidx++){
17
18 for (long hnum=0; hnum<PROCESS_COUNT; hnum++){
19 corpus_token_t tok = htabs[hnum * MAX_HASH_LENGTH + hidx];
20 if (tok.len>0) insert_token(tok, htab, corpus);
21 }
22 }
23 _exit(0);
24 }
25
26 }
27
28 wait_for_child_processes();
29
30 free(hsegs);
31
32 return htab;
33}
Done. I’m putting the pieces together and am dying to see the result. How long will my first method for creating the dictionary via parallel processing take? I run the algorithm on my computer using all of its 12 virtual cores.
Yippee! 111 seconds. Wow! That’s about 6 times faster than the single process C program and about 11 times faster than the second Python script. My wait time for creating a Wikipedia dictionary got slashed from 57 minutes to 23 minutes, to 13 minutes, to now less than 2 minutes.
Performance ... check. What about scalability?
I continue and deploy my code on the 2 Azure cloud servers.
Nope. Lesson #1 in the limitations of multiprocessing. The VM64 reaches its peak performance at 32 processes with an execution time of 50 seconds. Adding more cores, either in the VM64 or in the VM128, does not yield better performance. At some point, the cost of managing memory gobbles up all benefits of multiprocessing. Scalability ... X, beep.
| Multiprocessing with separate hashes | MacMini | MacMini | MacMini | VM64 | VM64 | VM64 | VM64 | VM128 | VM128 | VM128 |
|---|---|---|---|---|---|---|---|---|---|---|
| Number of processes | 2 | 6 | 12 | 12 | 16 | 32 | 64 | 64 | 96 | 128 |
| Processing time in seconds | 314 | 126 | 111 | 73 | 62 | 50 | 68 | 72 | 97 | 121 |
And off to round two.
2. Multiprocessing with semaphores for memory synchronization
Next, I want to test using memory synchronization which should help to address the memory problem associated with the previous method. My first option for memory synchronization are semaphores.
Semaphores are numeric registers that allow processes to make atomic operations. Atomic in this context means that an operation is guaranteed to be completed in one piece without interference from any other process. You can set a semaphore to a certain value, normally by incrementing or decrementing, and the operating system will ensure that only 1 process can access a defined resource, e.g. a memory address, at the same time.
Hhmmm… I’ve played with semaphores before and don’t hold them dearly.
Let’s see. I do want to give it a shot. To implement this technique I need to make only 2 changes: create and initialize one semaphore per hash table bucket, and lock (unlock) the respective semaphore before (after) I access the hash table.
Create and initialize one semaphore per hash table bucket
1#define SEMAPHORES_PER_SET 10000
2
3int *create_semaphore_sets(){
4
5 int semset_count = (int)(MAX_HASH_LENGTH / SEMAPHORES_PER_SET) + 1;
6
7 int *semset_ids = calloc(semset_count, sizeof(int));
8
9 for (int i=0; i<semset_count; i++)
10 if ((semset_ids[i] = semget(IPC_PRIVATE, SEMAPHORES_PER_SET, 0666 | IPC_CREAT))==-1) {perror("semget");exit(1);}
11
12
13 // reset all counters and semaphores
14 semun_t semun = {.val = 1}; // initial semaphore value => 1 = released
15 for (int setid=0; setid<semset_count; setid++)
16 for (int semid=0; semid<SEMAPHORES_PER_SET; semid++)
17 if(semctl(semset_ids[setid], semid, SETVAL, semun) == -1) {printf("semctl init for set %d sem %d: error %d \n",setid, semid, errno);exit(1);}
18
19 return semset_ids;
20}
21
22void remove_semaphore_sets(int *semset_ids){
23
24 int semset_count = (int)(MAX_HASH_LENGTH / SEMAPHORES_PER_SET) + 1;
25
26 for (int i=0; i<semset_count; i++)
27 if (semctl(semset_ids[i], 0, IPC_RMID) == -1) {perror("semctl remove");exit(1);}
28
29}
Lock and unlock the semaphore before and after access
1void lock_semaphore(int *semset_ids, size_t hidx){
2
3 int setid = (int)(hidx / SEMAPHORES_PER_SET);
4 int semid = hidx % SEMAPHORES_PER_SET;
5
6 struct sembuf sb;
7 sb.sem_num = semid;
8 sb.sem_flg = 0;
9 sb.sem_op = -1; // lock token
10 if (semop(semset_ids[setid], &sb, 1) == -1) {perror("semop");exit(1);}
11}
12
13void unlock_semaphore(int *semset_ids, size_t hidx){
14
15 int setid = (int)(hidx / SEMAPHORES_PER_SET);
16 int semid = hidx % SEMAPHORES_PER_SET;
17
18 struct sembuf sb;
19 sb.sem_num = semid;
20 sb.sem_flg = 0;
21 sb.sem_op = 1; // unlock token
22 if (semop(semset_ids[setid], &sb, 1) == -1) {perror("semop");exit(1);}
23}
With so many semaphores, I need to assign each semaphore to serve a particular token or hash table bucket. I use the token’s hash index hidx to do so. But, for the design to work, I will require about 30-40 million semaphores in total.
In most operating systems, however, there is a limit to the number of semaphores. I’m starting to wonder whether semaphores are the right tool for the job. While in Linux I can change the limit by editing:
1/proc/sys/kernel/sem
I wasn’t able to increase the limit high enough on my Mac to process the full corpus. Therefore, I proceed with testing this method on the Azure servers only. The result is devastating.
Slow as molasses, the semaphores keep crawling for 12,833 and 14,398 seconds to process the full English Wikipedia dump with 32 and 64 cores respectively. That’s almost 4 hours compared to less than 1 minute using the previous method. OMG. What an epic fail. Or, to be fair, just the wrong tool for the job. Locking and unlocking a semaphore requires making a low-level operating system call each time which simply does not scale.
| Multiprocessing with semaphores | VM64 | VM64 | VM64 | VM64 | VM64 | VM64 | VM128 | VM128 | VM128 |
|---|---|---|---|---|---|---|---|---|---|
| Number of processes | 2 | 6 | 12 | 16 | 32 | 64 | 64 | 96 | 128 |
| Processing time in seconds | 3,762 | 3,866 | 3,987 | 4,127 | 12,833 | 14,398 | n/a* | n/a* | n/a* |
* I did not complete the testing for semaphores on the VM128 due to an increasingly slow performance with higher process count.
One of the reasons semaphores are rather slow is that they work across processes. You could communicate between entirely different programs on the same machine which goes beyond what I need here.
3. Multithreading with mutexes for memory synchronization
Round 3. Mutexes are binary, process-specific registers that can be used to control access to a resource and support atomic operations in a multitask environment. Their usage is straight forward and the program design resembles what I’ve done above for semaphores. With one important difference. Mutexes do not work across processes but only within a single process.
Therefore, I switch from multiprocessing to multithreading and make the following 4 changes to the code:
- introduce a ‘thread object’,
- create and initialize one mutex per hash table bucket,
- define a start function for each thread, and
- lock (unlock) each mutex before (after) accessing the respective token.
Introduce a new ‘thread object’
One of the differences between using pthreads and fork is that when you send off a new thread you can only give it a single variable, or pointer, for the journey.
Therefore, I create a payload object corpus_thread_t which references all the variables each thread commands for its work.
1typedef struct corpus_thread_t{
2 char *corpus; // reference to corpus
3 size_t from_off; // reference to hash table
4 size_t to_off; // reference to mutexes array
5 corpus_token_t *htab; // reference to corpus segment start
6 pthread_mutex_t *mtxs; // reference to corpus segment end
7} corpus_thread_t;
Before I can inject the payload into the start function of a thread I need to initialize it with all the required values:
1corpus_thread_t *create_corpus_threads(char *corpus, range_t *corp_segs, corpus_token_t *htab){
2
3 corpus_thread_t *cts = malloc(PROCESS_COUNT * sizeof(corpus_thread_t));
4
5 for (int i=0; i<PROCESS_COUNT; i++){
6
7 cts[i].corpus = corpus;
8 cts[i].htab = htab;
9 cts[i].mtxs = NULL;
10 cts[i].from_off = corp_segs[i].from;
11 cts[i].to_off = corp_segs[i].to;
12 }
13
14 return cts;
15}
Ok. Each thread now receives an individualized corpus_thread_t payload object as a single variable. Only the mutexes are still missing. I add those in the next step.
Create and initialize one mutex per hash table bucket
My design prescribes one mutex per hash table bucket. Fortunately, C offers a built-in pthread_mutex_t object so I do not need to dream up my own. I just create an array of these mutex objects matching the size of the hash table. Before I wave them off with pthread_create I quickly toss in the missing reference to the mutexes.
1void process_corpus_multithreading(corpus_thread_t *cts){
2
3 pthread_mutex_t *mtxs = malloc(MAX_HASH_LENGTH * sizeof(pthread_mutex_t));
4
5 for (size_t i=0; i<MAX_HASH_LENGTH; i++) pthread_mutex_init (&mtxs[i], NULL);
6
7 pthread_t threads[PROCESS_COUNT];
8 for (long t=0; t<PROCESS_COUNT; t++){
9
10 // add the mutexes pointer into the thread objects
11 cts[t].mtxs = mtxs;
12
13 if (pthread_create(&threads[t], NULL, process_corpus_pt, (void *)&cts[t])) {perror("pthread_create");exit(-1);}
14
15 }
16
17 // wait for threads to exit
18 for (int t = 0;t<PROCESS_COUNT; t++) pthread_join(threads[t],NULL);
19
20 // remove the mutexes pointers
21 for (int i=0; i<PROCESS_COUNT; i++) cts[i].mtxs = NULL;
22 free(mtxs);
23}
Beware two differences of multithreading to multiprocessing: first, the hash table variable does not need to be a
mmapshared memory. A simplemallocsuffices since all threads share the same global memory space. Second, the parent process does notwaitfor a thread to finish but needs to join the thread. If you don’tpthread_jointhreads at the end you may get unpredictable results.
Define a start function for each thread
Each thread requires a start function. If you reviewed the above code you will have noticed that it references a function process_corpus_pt and passes the payload corpus_thread_t struct in the form of cts[t] to it. This is what my start function looks like:
1void *process_corpus_pt(void *arg){
2
3 // thread index
4 corpus_thread_t ct = *(corpus_thread_t*)arg;
5
6 corpus_token_t tok;
7 size_t str_pos = ct.from_off;
8 size_t str_end = ct.to_off;
9
10 while(str_pos < str_end){
11 tok = get_next_token(ct.corpus, &str_pos, str_end);
12 if (tok.len>0) insert_token_mt(0, tok, ct.htab, ct.corpus, ct.mtxs);
13 }
14 pthread_exit(NULL);
15}
I reference a new insert_token_mt function because the locking and unlocking for threads during a hash table insert work differently.
Lock and unlock the mutex before and after token access
The pthread library generously offers a lock and unlock function. Awesome. Thank you. I simply add the locking and unlocking into the thread-specific insert_token_mt function.
1void insert_token_mt(long pidx, corpus_token_t tok, corpus_token_t *htab, char *corpus, pthread_mutex_t *mtxs){
2
3 size_t hidx = get_token_hash(tok, corpus);
4
5 while(1) {
6
7 pthread_mutex_lock(&mtxs[pidx * MAX_HASH_LENGTH + hidx]);
8
9 // check if this bucket is empty
10 if (htab[hidx].len >0) {
11
12 // if the same token already exists in the hash table increment its counter
13 if (compare_corpus_tokens(&tok, htab+hidx, corpus) == 0) {
14 htab[hidx].count += tok.count;
15 pthread_mutex_unlock(&mtxs[pidx * MAX_HASH_LENGTH + hidx]);
16 return;
17
18 }
19 // otherwise move forward to the next bucket
20 else {
21 pthread_mutex_unlock(&mtxs[pidx * MAX_HASH_LENGTH + hidx]);
22 hidx++;
23 hidx %= MAX_HASH_LENGTH;
24 }
25
26 } else {
27 // if this token's bucket was empty (i.e. first time) add it into the hash table
28 htab[hidx] = tok;
29 pthread_mutex_unlock(&mtxs[pidx * MAX_HASH_LENGTH + hidx]);
30 return;
31 }
32 }
33}
Voila. Contender #3 is entering the ring. I can hardly sit tight. Will mutexes knock-out semaphores? Well, that’s not really the question, I hope. Running a BASIC script on a 286 can do that.
Yup. I’m happy with what I see. Creating the dictionary for the English Wikipedia dump takes only 122 seconds running 12 threads on my Mac Mini. That’s the second bests result so far. It’s a notch slower than the multiple hash tables method but consumes by far less memory. Nice. But how does it scale?
It doesn’t. Again. When I test this option on the cloud servers I find mutexes scale well to about 16 threads. At this point, performance hits a ceiling, and adding threads slows things down. Hmm. That’s unexpected. The overhead for locking and unlocking, plus the wait time if more than one thread wants to access the same token, eat up all the time gained from parallel processing.
| Multiprocessing with separate hashes | MacMini | MacMini | MacMini | VM64 | VM64 | VM64 | VM64 | VM128 | VM128 | VM128 |
|---|---|---|---|---|---|---|---|---|---|---|
| Number of processes | 2 | 6 | 12 | 12 | 16 | 32 | 64 | 64 | 96 | 128 |
| Processing time in seconds | 346 | 145 | 122 | 119 | 118 | 138 | 159 | 204 | 227 | 246 |
4. Multiprocessing with pipes for IPC
This leaves me with one last candidate to assess: pipes. Instead of communicating with each other by accessing the same memory, different processes send information in the form of messages to each other.
The interesting aspect of this messaging-based approach is that it should be scalable not only across multiple processes on the same machine, but also across multiple machines, if pipes, for example, were replaced by sockets.
Messaging-based design
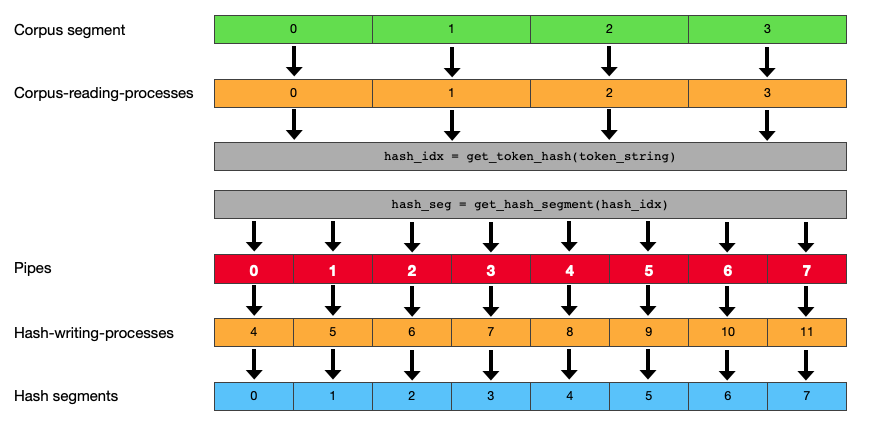
All 3 previous methods shared a similar design. Each process, or thread, works on a different segment of the corpus, reading and writing tokens. A messaging-based method must be designed differently. I will have 2 types of processes: one that reads, and one that writes. Tokens are sent as small messages via a pipe from a corpus-reading-process to a hash-table-writing-process.
Asynchronous inter process communication
One advantage of pipes is that they work fully asynchronous. The sender’s rate of writing into the pipe is not limited by the recipient’s rate of reading from the pipe. The pipe serves as a buffer and never loses a message. Huh. I can have different designs where there are either more senders or more receivers, depending on where I suspect a bottleneck. I could, for example, have only 4 processes that read the corpus (because I suspect this to be faster) and have 8 processes create the dictionary (because I suspect this to be slower). But how many pipes would I need in this case?
To avoid overlaps between processes I split the hash table into multiple segments and assign each hash-table-writing-process to one particular segment. Each process only receives the tokens that fit into its respective hash table segment.
Therefore, the number of pipes should match the number of processes that write to the hash table – which are the processes that read from the pipe BTW.
Be careful with the terms read and write in this context. Reading from the corpus means writing into the pipe. Reading from the pipe means writing into the hash table.
The processes that read the corpus know which pipe to send a token into by determining its hash segment via a reverse lookup. The following diagram summarizes this design – using an example of 4 processes that read the corpus, and 8 processes that write into the hash table.
Alright. Done the design, moving on to implementation. I add the following 4 functions to the code: create pipes, open and close pipes, send a token into a pipe, and read a token from a pipe.
Create pipes
A pipe is defined as an array of 2 integers. The 2 integers represent the 2 “channels” of the pipe. The 1st channel is for messages to come in, and the 2nd channel is for messages to go out. When the sender and receiver exchange information unidirectional, which is normally the case, I need only one of the channels and must close the other. I’ll come back to that later.
For coding convenience, I define pipes via below typedef which helps to access the incoming and outgoing channel of the pipe via a .in and .out attribute. I feel this keeps the code easier to read and avoids the usage of multi-dimensional arrays.
1typedef int pipe_arr_t[2];
2
3typedef struct pipe_t{
4 int in; // incoming
5 int out; // outgoing
6} pipe_t;
The downside of this typedeffing is an ugly cast for creating the pipes:
1pipe_t *create_pipes(long npipes){
2
3 // check that 80% capacity of the file descriptor limit is still available
4 if (npipes>MAX_FILE_DESCRIPTORS*0.8){printf("Max limit for file descriptors is not sufficient. ABORT\n");exit(1);}
5
6 pipe_t *pipes = malloc(npipes * sizeof(pipe_t));
7
8 for (long i=0; i<npipes; i++)
9 if (pipe(*(pipe_arr_t*)&pipes[i]) == -1) {printf("Error when creating pipes. ABORT\n");exit(1);}
10
11 return pipes;
12}
Open and close pipes
After the pipes have been created and forked, each process carries a copy of all pipes. The key to the usage of pipes is that all pipe copies need to be closed properly for the pipe to work. And for each pipe copy, each channel (the incoming and the outgoing) must be closed separately. Not closing all pipes' in- and out-channels is a frequent source of errors.
1void close_pipes_in(pipe_t *pipes, long npipes){
2 for (long i=0; i<npipes; i++)
3 if (close(pipes[i].in) == -1){printf("Error when closing 'in' pipes. ABORT\n");exit(1);}
4}
5
6void close_pipes_out(pipe_t *pipes, long npipes){
7 for (long i=0; i<npipes; i++)
8 if (close(pipes[i].out) == -1){printf("Error when closing 'in' pipes. ABORT\n");exit(1);}
9}
Send a token into a pipe
When I send tokens into the pipe, I need to use the out channel. That’s obvious. What’s less obvious though is that, and I know I’m repeating myself here, I should therefore close the in-channel right away. Below function shows how this looks like:
1void read_corpus_and_send_tokens_into_pipe_mp(long pidx, char *corpus, range_t *corp_segs, pipe_t *pipes){
2
3 close_pipes_in(pipes, PROCESS_COUNT_WRITE_HASH);
4
5 size_t str_pos = corp_segs[pidx].from;
6 size_t str_end = corp_segs[pidx].to;
7
8 corpus_token_t tok;
9 while(str_pos < str_end){
10 tok = get_next_token(corpus, &str_pos, str_end);
11
12 if (tok.len>0) {
13
14 // find the index of the pipe/hash-segment that should be used for this token
15 size_t hash = get_token_hash(tok, corpus);
16 long seg_idx = get_segment_index(hash, MAX_HASH_LENGTH, PROCESS_COUNT_WRITE_HASH);
17
18 // send the token into the selected pipe
19 if (write(pipes[seg_idx].out, &tok, sizeof(corpus_token_t)) == -1) printf("Error sending token into the pipe!\n");
20 }
21 }
22 close_pipes_out(pipes, PROCESS_COUNT_WRITE_HASH);
23}
Read a token from a pipe
Reading the pipe is straight forward. I simply loop a read function scanning the in channel until the other end of the pipe gets closed.
1void read_pipe_and_write_tokens_into_htab(long pidx, char *corpus, corpus_token_t *htab, pipe_t *pipes){
2
3 close_pipes_out(pipes, PROCESS_COUNT_WRITE_HASH);
4
5 // read the pipe of this process until all sending is closed
6 corpus_token_t tok;
7 while (read(pipes[pidx].in, &tok, sizeof(tok))) insert_token(tok, htab, corpus);
8
9 close_pipes_in(pipes, PROCESS_COUNT_WRITE_HASH);
10}
And again, I must close the unused channel, in this case, the out channel, in the beginning of the function. Similarly, at the end of the function, I need to close all in channels as well, since they are not used anymore. (Ok. I’m not mentioning closing pipes anymore.)
That’s it. All that’s left is to add these 2 functions into a multiprocessing loop. I call the respective function process_corpus_pipes:
1PROCESS_COUNT_READ_CORPUS = PROCESS_COUNT/2; // half of the processes read the corpus
2PROCESS_COUNT_WRITE_HASH = PROCESS_COUNT/2; // half of the processes write the hash table
3
4void process_corpus_pipes(char *corpus, size_t corpus_fsize, range_t *corp_segs, corpus_token_t *htab, range_t *htab_segs){
5
6 if (PROCESS_COUNT<2) {process_corpus_mp(0, corpus, 0, corpus_fsize, htab, NULL);return;}
7
8 pipe_t *pipes = create_pipes(PROCESS_COUNT_WRITE_HASH);
9
10 int pid;
11
12 // Part 1 -- Kick-off the reading-corpus-processes
13 for (long pidx=0; pidx<PROCESS_COUNT_READ_CORPUS; pidx++){
14
15 if ((pid = fork()) < 0) {perror("fork");exit(1);}
16
17 if (pid==0){
18 read_corpus_and_send_tokens_into_pipe_mp(pidx, corpus, corp_segs, pipes);
19 _exit(0);
20 }
21 }
22
23
24 // Part 2 -- Kick-off the write-hash-processes
25 for (long pidx=0; pidx<PROCESS_COUNT_WRITE_HASH; pidx++){
26
27 if ((pid = fork()) < 0) {perror("fork");exit(1);}
28
29 if (pid==0){
30 read_pipe_and_write_tokens_into_htab(pidx, corpus, htab, pipes);
31 _exit(0);
32 }
33 }
34
35 // close parent process pipes
36 close_pipes_in (pipes, PROCESS_COUNT_WRITE_HASH);
37 close_pipes_out(pipes, PROCESS_COUNT_WRITE_HASH);
38
39 wait_for_child_processes();
40
41 free(pipes);
42}
Note that the
wait_for_child_processes()occurs after closing the pipes. If the parent process does not also close all of its pipes the child processes won’t exit. (Oops. Another ‘closing pipes’. I promise this is the last one.)
Ok. Now let me run it and see how multiprocessing with pipes compares to the previous methods.
Ta-dah. As expected. Sending tokens as messages back and forth between processes is slower than accessing shared memory. Nevertheless, it’s nothing to sneeze at. The pipes take ‘only’ 1,704 seconds on my computer to create the dictionary which is a little longer than the second Python script. And what I cherish about this option is its decentralized, messaging-based architecture. How about processing a text across multiple machines via a distributed system? Sounds like another enthralling project to come.
Here’s a summary of the pipes testing:
| Multiprocessing with pipes for IPC | MacMini | MacMini | MacMini | VM64 | VM64 | VM64 | VM64 | VM128 | VM128 | VM128 |
|---|---|---|---|---|---|---|---|---|---|---|
| Number of processes | 2 | 6 | 12 | 12 | 16 | 32 | 64 | 64 | 96 | 128 |
| Processing time in seconds | 2,903 | 2,363 | 1.704 | 958 | 1,636 | 4,500 | 10,229 | 13,637 | n/a* | n/a* |
- I did not test pipes with more than 64 cores on the VM128 since performance clearly deteriorated rapidly with a higher process count.
Huh… almost done. I finished my testing of 4 methods of parallel processing:
- 2 of them performed splendidly (mutexes and multiple hashes),
- 1 of them reasonably well (pipes) and
- 1 of them fell flat (semaphores).
Yet, none of them scaled. I had expected that for at least one of the methods adding cores would always further increase performance. Obviously, this is not the case. The overhead of managing and coordinating multiple processes, be it memory management, locking and unlocking registers, or sending and receiving messages, eventually outweighs the benefits of parallel processing.
Hmmm.. wait. This leaves one question open. If it’s the overhead that’s preventing the scaling, and the overhead only exists because of our task of creating a dictionary, then how about if I simply read the corpus. No deduplication, no hash table, just read the text, word by word.
Last but not least: just read
Before I conclude my testing I’m adding another option, just for fun. And curiosity. I want to confirm whether multiprocessing or multithreading can scale at all. Is running multiple processes or threads burdened with inherent overhead? If I simply read the Wikipedia text, without deduplicating tokens and creating a dictionary, will performance consistently improve all the way to 128 cores?
Before I conclude my adventure, I thus create a simple function process_corpus_reading_only and test it on all 3 machines.
1void process_corpus_reading_only(char *corpus, size_t corpus_fsize){
2
3 range_t *segs = create_corpus_segments(corpus_fsize, PROCESS_COUNT, corpus);
4
5 int pid;
6
7 for (long pidx=0; pidx<PROCESS_COUNT; pidx++){
8
9 if ((pid = fork()) < 0) {perror("fork");exit(1);}
10
11 if (pid==0){
12
13 size_t pos =segs[pidx].from;
14 size_t end =segs[pidx].to;
15
16 corpus_token_t tok;
17 while(pos < end){
18 tok = get_next_token(corpus, &pos, end);
19 }
20 _exit(0);
21 }
22 }
23
24 wait_for_child_processes();
25 free(segs);
26 return;
27}
Wow! Finally. 2 processes run faster than 6, which run faster than 12, which run faster than 32, etc. All the way to 128 processes which take a mere 6 seconds to read through the full 17 GB English Wikipedia corpus with approx. 2.8 billion words. That’s a whopping 460 million words per second. To put this in perspective: if an average novel nowadays comprises 90,000 words, then text2dict is reading 5,000 books ... per second.
| Simply reading the corpus, without creating a dictionary | MacMini | MacMini | MacMini | VM64 | VM64 | VM64 | VM64 | VM128 | VM128 | VM128 |
|---|---|---|---|---|---|---|---|---|---|---|
| Number of processes | 2 | 6 | 12 | 12 | 16 | 32 | 64 | 64 | 96 | 128 |
| Processing time in seconds | 75 | 63 | 60 | 31 | 22 | 12 | 9 | 8 | 7 | 6 |
At this point, I’m wondering how long this would take on the VM416 that I didn’t get to test on. With more than 3 times the number of cores than the VM128, could the VM416 reduce the processing time further ... to 2 seconds?
Here is the summary of all of the above results, consolidated in one table:
| Processing time in seconds | MacMini | MacMini | MacMini | VM64 | VM64 | VM64 | VM64 | VM128 | VM128 | VM128 |
|---|---|---|---|---|---|---|---|---|---|---|
| # of processes / threads | 2 | 6 | 12 | 12 | 16 | 32 | 64 | 64 | 96 | 128 |
| Semaphores | 3,762 | 3,866 | 3,987 | 3,987 | 4,127 | 12,833 | 14,398 | n/a* | n/a* | n/a* |
| Pipes | 2,903 | 2,363 | 1.704 | 958 | 1,636 | 4,500 | 10,229 | 13,637 | n/a* | n/a* |
| Mutexes | 346 | 145 | 122 | 119 | 118 | 138 | 159 | 204 | 227 | 246 |
| Multiples hashes | 314 | 126 | 111 | 73 | 62 | 50 | 68 | 72 | 97 | 121 |
| Reading corpus | 175 | 63 | 60 | 31 | 22 | 12 | 9 | 8 | 7 | 6 |
* I did not test semaphores and pipes on more than 64 cores since performance clearly deteriorated rapidly with a higher process count.|||||||||||
Summary and conclusion
Given the simple task of creating a dictionary from the Wikipedia corpus, I detoured into insightful analysis and comparison of 4 different methods of parallel processing large text files. On this journey, I learned about the power and potential of multiprocessing and multithreading, but also its challenges and limitations.
Working with large data sources has become the norm. File sizes that developers and data scientists work on grow exponentially. And large is never large enough. While the usage of GPUs has become very popular through deep learning, the effective utilization of multiple CPUs to enhance processing performance is still lingering.
Bigger machines with more memory will hopefully enable and motivate more developers to embrace parallel processing. As I’ve shown in this post, the challenge of handling race conditions can be addressed in different ways. And sometimes, the most effective one is simply ‘throwing memory at the problem’.
Lessons learned
These are some of the key technical lessons I learned from this exercise. Some of them expected, some other less so:
- Reading a file fully into memory is not faster than mmap. On the contrary, mmap performed consistently better, albeit only slightly.
- Multiprocessing and multithreading have roughly the same performance. On average, running multiple processes (i.e. using fork) was somewhat faster than running the same number of threads.
- The fastest technique for addressing race conditions is to avoid them, e.g. by throwing memory at the problem.
- The most efficient technique, in terms of memory usage and performance, is memory synchronization using mutexes.
- Stay away from semaphores, at least for anything that requires usage on a large scale.
- None of the methods scales really well with multiple cores. Peak performance is reached around 32 cores and then gradually decreases.
- What does scale is simply reading the corpus without any process coordination whatsoever. How far this can be scaled is to be explored on bigger machines.
Processing other Wikipedia languages
At last, I used the fastest technique to see how long the process of creating a dictionary and of simply reading the Wikipedia corpus takes for other languages than English. Here’s a summary:
| Wikipedia language | token type | file size | tokens in corpus | avg. token length | tokens in dict | fastest creation of dict | fastest read of corpus | top 10 tokens |
|---|---|---|---|---|---|---|---|---|
| English | word | 17.3 GB | 2.8 billion | 6.2 | 9.9 million | 50 seconds | 6 seconds | the, of, and, in, to, was, is, for, on, as |
| German | word | 7.5 GB | 1.1 billion | 7.0 | 7.8 million | 29 seconds | 2 seconds | der, und, die, in, von, im, des, den kategorie, mit |
| French | word | 6.3 GB | 982 million | 6.4 | 4.9 million | 25 seconds | 2 seconds | de, la, le, et, en, du, des, les, est, un |
| Spanish | word | 4.8 GB | 743 million | 6.4 | 4.1 million | 21 seconds | 1 second | de, la, en, el, del, que, los, se, por, un |
| Italian | word | 3.9 GB | 584 million | 6.7 | 3.7 million | 19 seconds | 1 second | di, il, la, in, del, un, che, della, per, nel |
| Portuguese | word | 2.2 GB | 324 million | 6.7 | 2.6 million | 15 seconds | 1 second | de, em, do, da, que, no, um, com, uma, para |
| Russian | word | 7.8 GB | 554 million | 14.1 | 6.6 million | 26 seconds | 2 seconds | на, года, категория, по, году, из, не, был, от, за |
| Japanese | character | 3.1 GB | 944 million | 3.3 | 1.6 million | 26 seconds | 1 second | の, ー, ン, に, は, ス, た, ル, る, と |
| Chinese | character | 1.3 GB | 406 million | 3.3 | 1.4 million | 48 seconds | <1 second | 的, 中, 一, 年, 大, 在, 人, 是, 有, 行 |
P.S.: It’s interesting to see that the average token length in European languages is almost the same. They also share very similar words in their top 10 of the most frequently used words. One could argue that the top 10 shows how ‘inefficient’ these languages are given that most top 10 words are ‘low-value’ prepositions. In contrast, in Chinese, you can find nouns, verbs, and adjectives among the top 10 which arguably indicates a higher efficiency in the language.
Source code
I have consolidated all code from this blog post into a project called text2dict. Here is the Github repository.
text2dict supports a command-line interface for easily converting text files to a dictionary using a user-defined number of parallel processes. It supports all methods introduced in this post. Feel free to compare results for your own hardware.
Thanks for reading. Feel free to share your comments or raise any questions below.
Happy coding!